Download Mozilla Firefox with the Google Toolbar - FREE
Mozilla's new version of its immensely popular browser, Firefox 3, is coming along nicely. If you are one to keep abreast of the latest tech news, you probably heard about a lot of planned features and possibly saw a handful of mockups to go with it. In fact Mozilla provides a rather in-depth (and up-to-date) list of features that are planned, and their current status. Take a look for yourself.
For those of you who don't want to pick out the good bits from the overwhelmingly comprehensive list, here's the top five features that would make Firefox 3 stand out from the rest.
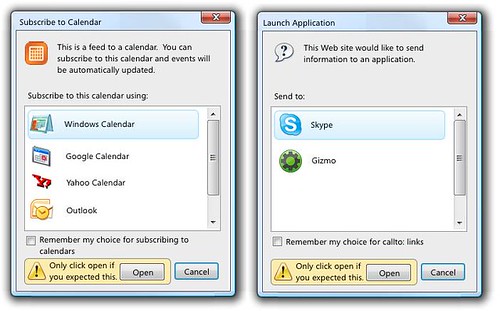
1. Support web services as protocol handlers
This means Firefox can now properly identify individual file-types, and can carry out the default (or preferred) action. In Firefox 2, this just works for some (RSS Feeds and extensions), while most other file-types simply triggers the download prompt. Starting with Firefox 3, you'll be able to manage how images, microformats, podcasts, etc. are handled. Another interesting bit, is that whenever you find a page having such an element the mouse pointer will change shape to illustrate the default action. The mockups should clarify further.

2. A redesigned Download Manager
A brand new Download Manager that greatly improves on its predecessor. Now Firefox can pause and resume downloads across multiple sessions, and integrates with third-party virus and malware scanners to ensure you're security.The most interesting new addition is the ability to search through the downloads, although I personally won't find much use for that, many users will probably love it.

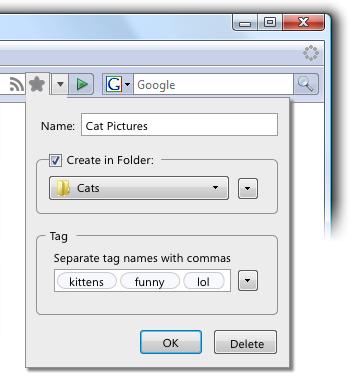
3. Better Bookmarking Feature
Bookmarking has never really been a strength for Firefox, and most people ended up using some external (social) bookmarking service instead. Mozilla has however finally wised up and added a quick and easy way to bookmark a page, you simply click the star on the address bar and a menu slides out letting you name and tag the page. Take note however that this mockup isn't up-to-date, and the final iteration is slightly more aesthetically pleasing.
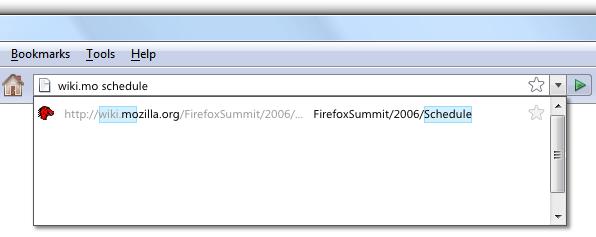
4. History Search
This is possibly the best history search feature on any browser yet. You can search using multiple terms, that are searched for in the address and the title of the page, The star next to the results indicate how many times you visited the page, and therefore how interested you are in it (see the entire mockup), the darker the star the higher the interest, with a yellow star indicating a bookmarked page. Also note how part of the URL is faded, this is another unique feature of Firefox 3 that intends to make URLs more human readable.
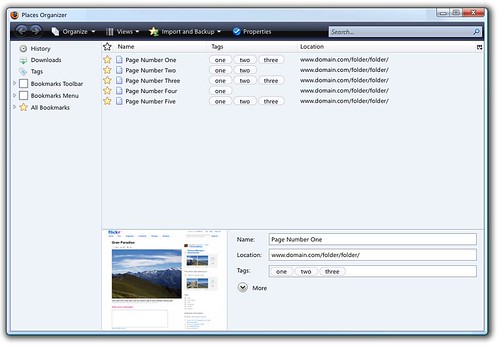
5. Places (Yes, we're finally getting it)
Places is a unique yet simple method to unify and manage History and Bookmarking in Firefox, with a great tagging implementation and search feature. Places has been the most coveted feature for Firefox. Initially said to make its appearance in Firefox 2, users were sorely disappointed when it was cut from that release, now finally Places is all set to make its debut in Firefox 3, complete with a sleek (Vista-esque) interface, although I wonder how it'll look on non-Vista operating systems.
Other than these five features there are myriads of other minor (a permamnent Restart button) and major (under the hood tweaks) additions and updates to Firefox that truly make Mozilla Firefox 3 a release to look forward to.
Read More...
Summary only...



{kind=link}